
深度观察
近日举行的“亚布力中国企业家论坛第25届年会”上,复星国际董事长郭广昌表示,“我的助理帮我写这篇稿子的时候,也让DeepSeek和阿里通义千问等人工智能平台都作了个比较,可以说是各有特点,也感谢这些平台,我们也是受益者。”不仅是企业家大佬们,“遇上事都DeepSeek一下”,成为众多人的“口头禅”。
大模型真的变成“上知天文,下知地理”的小能手?本期,全媒体记者实测当下六款主流AIGC产品,包括百度的文小言、腾讯的元宝、字节的豆包、阿里的通义、科大讯飞的星火以及DeepSeek,一探谁才是大模型界的“六边形战士”。
文、表/广州日报全媒体记者 文静、邓莉、张露
实测1
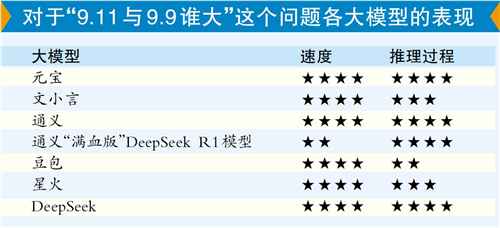
要求:比较9.11与9.9谁大?
六模型答案都对 解题步骤详细程度不同
去年大模型刚开始“落地”时,当时有媒体向多家大模型提问,当时多个主流大模型都没给出正确答案,包括ChatGPT-4o回答是9.11比9.9大。随着DeepSeek的登场,多家模型也不断接受训练,同样的问题,现在的回答如何?
包括DeekSeep在内的六家模型给这一题的答案都是9.9比9.11大,显然经过了一轮用户的训练,模型更懂得用户需求从数值比较的语境下理解。不过,通义千问就提出,假如是从日期上判断,会给出两个不同答案。
对于9.11与9.9谁大的问题,腾讯元宝(接入DeepSeek版)经过12秒的深度思考,给出的答案是9.9比9.11大。其罗列了详细的步骤解释,提及的关键点是:“比较小数时,若位数不同,需先补齐位数,再从高位到低位依次比较,直到确定大小为止。”百度文小言(接入DeepSeek-R1版)给出的正确答案是9.9比9.11大。除了答案,它也给出了推导过程。其推导过程没有DeepSeek详细,但它提供关于9.11与9.9谁更大这个问题,在知乎、微信平台公众号、自媒体号以及短视频平台的内容链接。
对这个数学题,通义千问全程思考5秒,稍微有分析,显示简单判断逻辑,并且通过数值和日期,给出了两个答案。豆包则是3秒,回答非常简单,仅从数值角度判断得出9.9更大。若对阿里通义“满血版”DeepSeek R1模型提问,全程漫长,大约一分钟,但跟DeepSeek一样有较长的推理分析。至于讯飞星火,也是输入问题后,几秒钟就给出解题思路,判断9.9大于9.11。
实测2
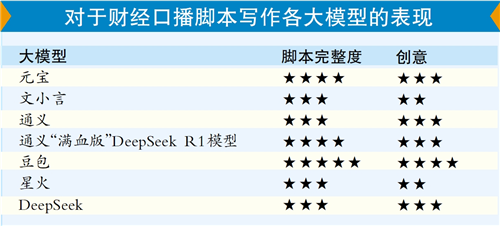
要求:财经口播脚本写作
元宝脚本易“同质化” 豆包脚本更完整
现在许多媒体人都会利用大模型来写文案、写脚本,提升工作效率。同时,许多大模型也宣传自身强大的语言能力,并且能根据不同平台的调性进行文案写作。到底实力如何?
记者在大模型中输入提示词:我是一名财经博主,请结合当下最热的财经风口写一篇财经口播脚本,开头有“钩子”,中间有干货,结尾有互动。
腾讯元宝DeepSeek版深度思考后给出记者的财经热点建议,包括了“AI应用爆发”“低空经济”“人形机器人”三大风口。脚本开头如何吸引观众?它提供的话术是:“家人们!注意了!(手势指屏幕)英伟达刚交完2024年Q1财报,GPU交货排到2025年!这意味着什么?(停顿1秒)AI算力竞赛已经白热化!(敲桌)今天带你挖出藏在财报里的3个暴富代码!”这个脚本更偏向“口水”短视频风格,容易出现同质化。
文小言大概5秒开始生成口播脚本,整体感觉中规中矩,也没有安排镜头或动作等,主要是旁白内容。
讯飞星火给到的财经风口是人工智能与自动化主题。整体脚本较为中规中矩,开头不够吸引人。主播的开场白设定为:“大家好,欢迎收看本期《财经前沿》,我是你们的主播XXX。今天我们将一起探讨一个改变未来的力量——人工智能与自动化。”
在记者看来,豆包的脚本更贴近自媒体博主的需求,脚本以表格形式非常详细、清晰地将文本、配乐、画面、时长、镜头景别都进行了分类显示,尤其是在画面分镜中,还“指导”主播的一些动作语言和切换内容。口播内容上,通过“五个风口”的总结,鲜明地点出当下热点,比较契合提问。
阿里通义“满血版”DeepSeek R1模型深度思考后,生成时间大约20秒,主题鲜明,聚焦“低空经济”赛道生成纯文本的口播内容。全文700字左右。文本脚本中,有口播表情、手势、播放ppt等建议,最后还补充了口播风格适当加入的范围推荐。但具体来看不如豆包精确到时间的完整度高。
DeepSeek在脚本加入了金融投资案例,还给了投资建议,看起来更切合财经类受众的需求,但是脚本完整性不如元宝、豆包等。
实测3
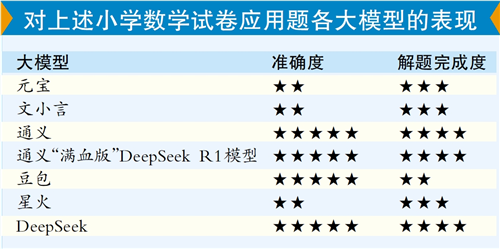
要求:解答小学数学应用题
三家模型答案正确
今年1月,某地小学数学试卷引发热议,网友纷纷称其为“难出天际”的数学试卷。如今,在学生学习的过程中,越来越多家长都会用上大模型应用作为助手,帮助孩子解题并提供解题思路。记者从这份“难出天际”的小学四年级试卷中随机抽取一道应用题,看看六家模型会给出怎样的答案。
记者在大模型中输入题目:如今,在驿站中能凭借精准的取件码领取快递。已知取件码“8-2-1007”表示“星期一的第7个快递,在第8个货柜的第2层”。有一份快递是星期五的第104个快递,在第3个货柜的第4层。这份快递的取件码是多少?
先从结果看,DeepSeek、豆包以及阿里通义给出一致的答案,快递取件码是“3-4-5104”,腾讯元宝、文小言以及讯飞星火都各有差异。
记者实测发现,对于这道小学试卷应用题,通义千问和豆包都几乎在3秒内算出答案,看来“难出天际”没有难倒它们。此外,阿里通义“满血版”DeepSeek R1模型,经过了非常详尽和冗长的解题思路,实测耗时3分多钟,让人有点“熬不住”。腾讯元宝(接入DeepSeek版)经过思考后提出,“星期”对应的代码为10~16,因此,给出的答案是“3-4-14104”。讯飞星火在一开始时,答题思路就有错误,最开始理解取件码的结构出错了,进而答案变成了“5-104-3-4”。文小言给出的答案中,也是对取件码的组成规则理解有误,组合出来结果就变成了“5-3-104-4”。
为何在数学问题上,生成式大模型容易产生错误?
对此,云蝶科技CTO陈天博士向广州日报记者解释,如果不做特殊处理,大模型采用的是无监督学习,吐字的底层原理是统计学,它通过对大量文本数据的学习,来预测下一个词或字符应该出什么?本质上并没有理解数学问题,也不适合做逻辑上的处理。但是现在越来越多的模型注意到这个问题,在训练时使用监督学习方式,训练过程中使用大量高质量的数学材料,通过思维链方式模拟人类解决问题的思路,所以现在对数学问题的处理能力强了很多。
实测4
要求:测试多模态能力
五家模型具备多模态优势
纵观上述六家大模型应用,DeepSeek-V3是专注于文本处理,不具备多模态识别的功能。目前DeepSeek App其AI功能也相对简单,除了在对话框中输入提示词,仅具备拍照识文字、图片识文字以及文件上传等功能。
其他五家模型则具备多模态优势。通义千问在ppt制作、实时记录、AI扩图、周报助手等方面都有优势。豆包广受在校学生欢迎,尤其采用了拟人化的设计风格,通过微信对话框的形式与用户进行交互,增进了用户的亲近感。讯飞星火在语音识别和生成方面具有较强的能力,能够处理复杂的语音信息并生成相应的文本描述。文小言拥有丰富的智能体,包括聊天、写作、娱乐、绘画、办公等,而每项功能下再有细分类目。
另一方面,记者留意到,目前只有豆包尚未接入DeepSeek,但在推理领域最近亦迎来新的进展。2月25日消息,字节跳动旗下AI助手豆包正在小范围测试深度思考模型,但接入的不是DeepSeek模型。豆包相关负责人表示,当前测试的是自己深度思考模型的不同实验版本。记者实测发现,目前,在豆包对话页面暂未显示“深度思考”功能的入口,但若灰度用户(产品正式发布前特定的试用人群)在询问不同问题后,豆包生成的答复中会显示思维链。在这场深度思考模型的竞赛中,豆包的步伐似乎稍显滞后。
阿里则在接入DeepSeek后,加速自研推理模型,2月25日,阿里Qwen团队发布新推理模型——深度思考 (QwQ),该模型由QwQ-Max-Preview支持,基于Qwen2.5-Max,擅长数学理解、编程、AI智能体等,其是类似 DeepSeek R1和kimi的推理模型,可同时支持深度思考和联网搜索,并展示完整思维链。目前已在通义千问的新官网上线。在上周,腾讯元宝接入DeepSeek的同时,宣布了其自研深度思考模型混元T1上线。
业内观点
对话模型与推理模型在体验感上有区别
不同平台大模型各有各的特点。不少用户有疑问:为什么以DeepSeek为代表的推理模型与其他主流对话模型相比“看起来更聪明”?
“对话模型像一个心直口快的人,基本没有思考过程,就很着急地快速处理了跟你的‘闲聊’对话;推理模型则像个研究人员,一步步拆解问题,具有更长的思维链,不仅能给出答案,还会给出它详细的思考过程。”
一位接近阿里云的人士解释了对话模型与推理模型的区别。他表示,在两者的区别上,对话模型的特点是“注重及时回复,无思考过程,能快速处理闲聊,可语音视频通话,直接给出答案无详细思考”。推理模型的特点是“不仅给答案,还有详细思考过程与长思维链,能对比不同方法、反向验证,思考用户切实需求”。
上述人士举例称,在实际案例中,如数学题场景,对话模型会直接给出答案步骤,推理模型则会给出思考过程,并对比算术与代数方法。在生活场景方面,如一个预算2万元购买纯电动车的选择问题,对话模型未能及时识别预算与产品冲突,推理模型则会给出车型对比、指出预算不足并推荐其他车型及提示风险。
在日常推荐场景方面,面对推荐餐厅时,对话模型大概率只会直接推荐高分餐厅,推理模型则会询问距离、价格等实际需求。
行业观察
大模型将在多个维度变得更加“聪明”
大模型去年正式“落地”,多款产品陆续开放给C端用户,今年初DeepSeek则带动了推理模型的爆发。从应用体验,上述多款主流模型相比刚推出时,不管是使用的流畅度、反馈速度、准确性、内容丰富度以及中文能力等,都有很大的提升,随着多家大厂进入推理模型的“赛道”,相信这类模型的能力能得到快速提升。
经过本轮实测体验,以及记者采访多位使用者,关于未来有怎样体验感的产品,才能称得上真正的AI助手的问题,总结了三点:首先,模型提供的内容要准确,不能出现“幻觉”,一味地“胡说八道”。除了数学题之外,有网友发现有大模型会“无中生有”,将根本没有的典籍、典故作为内容推给用户。其次,模型的反应速度要迅速。“我使用它就是有需求,假如每次我输入提示词后App都显示‘服务器繁忙’,就很容易让人失望。”消费者张小姐告诉记者。最后,作为提升工作效率的AI助手,模型的专业程度要高,能给到专业的意见和内容,而不是网络上同质化的东西。
随着人工智能技术的不断演进,大模型的发展路径愈发清晰,其技术路线、用户体验和市场格局正呈现出多维度的变革趋势。
“从技术路线上,未来大模型的发展将聚焦于多模态融合、轻量化、强推理、行业定制化和具身智能等领域。”深度科技研究院院长张孝荣表示,这将推动AI技术在更多复杂场景中的应用,并提升其在各行业的价值。随着人工智能技术的发展,未来大模型的技术路线可能会更加多元化,包括引入更多的自然语言处理、计算机视觉、知识图谱等技术,以提高大模型的性能和可靠性。
从用户角度来看,天使投资人、资深人工智能专家郭涛直言,大模型将在多个维度变得更加“聪明”。在理解能力上,能更精准地把握用户意图。在应用场景上会更加广泛,除了现有的领域,还会深入到医疗、教育、法律等专业领域,为用户提供专业的建议和解决方案。
从市场格局来看,张孝荣认为,未来不同平台的大模型可能会在差异化发展和竞争共存中取得平衡。由于不同平台的大模型各有特点,未来的市场竞争可能会更加激烈。但同时,随着技术的发展和应用的普及,不同平台的大模型可能会逐渐走向融合和互操作性,实现互利共赢。